Chapter 9 Visual search
From time to time, we all need to find things. Rummaging through our closet for a particular shirt, or wandering about the house trying to find our keys, or for some of us, groping about for our spectacles that we know we put down somewhere around here.
Our search performance patterns can reveal aspects of the bottlenecks in mental processing. Slow search may indicate a bottleneck is affecting processing. However, sometimes search is slow because the basic sensory signals are not good. For example, when I lose my spectacles, my vision is so poor that I have to bring my face close to each location in the room to check whether my glasses are there. Similarly, wandering about the house looking for one’s keys, if one is to evaluate all the rooms of the house for the presence of the keys, one has to visit each room.
Sometimes, even though something is right in front of our face and we have our glasses or contact lenses on, the sensory signals still aren’t good enough for it to be possible to know that the object is there. For example, try searching for the word “wilt” in the below image.

Figure 9.1: The first two pages of Romeo and Juliet.
Did you find ‘wilt’ yet? To find it, your eyes have to move back and forth. The task is impossible to do without moving your eyes (‘wilt’ is about 3/4 of the way down the left page). The main reason you have to move your eyes is that the sensory signals provided by your retinas are only good enough to read small words near the center of your vision. So, you have to move your eyes.
To experience this sad fact about your vision more directly, try the following. Stare directly at the black cross and, while keeping your eyes fixed on the cross, try reading any of the words on the bottom of the page. You can’t do it. Not because of any bottleneck, or problem with selection, but simply because your photoreceptors are too widely spaced in the periphery. That is, outside of a central region, the spatial resolution of your vision is too low to see many details. The sensory signals from the periphery are coarse.
Thus, not only are overt attentional shifts (eye movements) often made when you want to attentionally select a region of space, but also sometimes covert attention isn’t sufficient - you have to move your eyes to have any chance of seeing certain things well enough to know what they are.
9.1 Information overload
A good way to assess whether there is a bottleneck in a system is to give it more and more things to process and see whether this degrades performance or whether the system can process them all just as quickly as when it is given only one. Psychologists did this for visual processing by giving people many stimuli to process, by adding more and more to a display. In doing this, however, they had to be careful to make sure that the brain had a chance, by making sure that a person could see each individual stimulus even when it wasn’t in the center of their vision (unlike in the Romeo & Juliet demonstration above). If the person couldn’t even see the stimuli well, then of course the brain wouldn’t process it sufficiently even if it didn’t have a bottleneck.
One of the tasks psychologists have used for this is called “visual search”. In a visual search experiment, people are shown a display with a particular number of stimuli and asked to find a target. This is discussed this in first-year psychology. The next section is, in part, a review of that.
9.2 Parallel search
In a previous chapter (7), you learned that you can select stimuli by their location, or by an individual feature such as a particular color. That is, if you just think about a particular location, or a particular color, your attention tends to go the appropriate place(s). For example, if you think “blue” while looking at the display below, your attention will go to the blue dots quite quickly. Stare at the center of their display and concentrate on selecting the blue dots.

To capture this effect in experiments, researchers typically present lots of object, but only one with the target characteristic. The task is to press a key if the target is present, and in half of trials the researchers present the display with no target.

The data indicate that people can find a blue object quickly no matter how many other objects there are in the display. This is called “parallel search” because the evaluation of objects occurs simultaneously across the entire scene. In other words, the processing happens before the major bottlenecks of the brain.
The associated pattern of experiment results is demonstrated by the graph below.
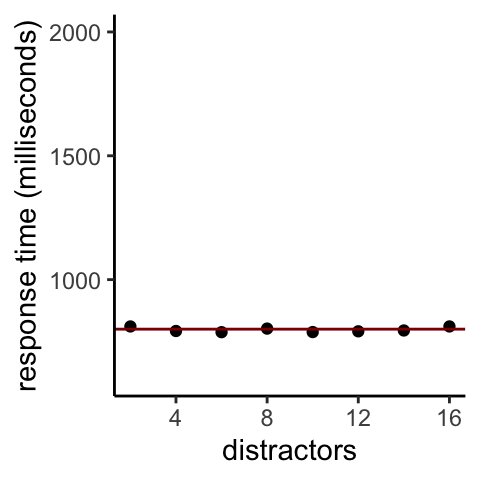
Figure 9.2: Time to find a lone blue circle among red and green circles
The diagram below provides a basic idea of the processing stages involved. The first stages of your visual brain determine the color of each object in the display, processing them all simultaneously. Then, by simply thinking about red, the red neurons’ activity is enhanced and your focused attention will end up going to the location of any red objects present.
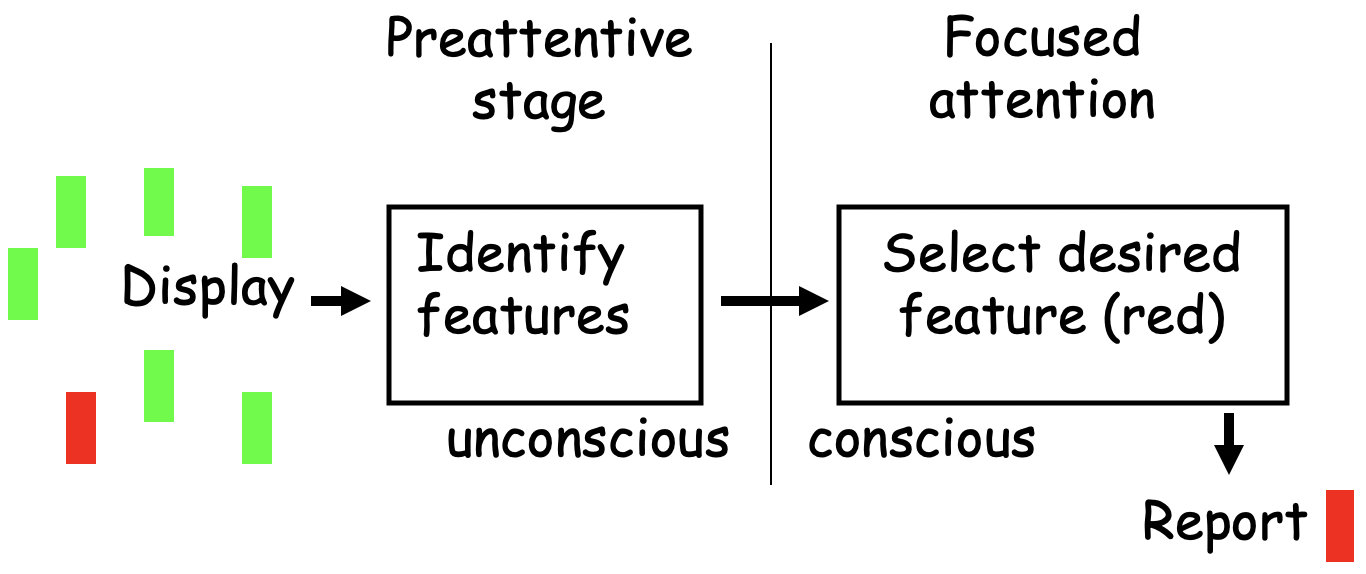
9.2.1 Bottom-up attention also plays a role
A complication in visual search experiments for a lone target (like a lone blue circle in a sea of red and green) is that it is the only item in that display which has that feature. As described in 5, bottom-up attention will drive attention toward the location of the uniquely-colored object.
For a search like for the blue target above, then, both feature selection (thinking “blue”) and bottom-up attention combine to make the search particularly easy.
9.3 Processing one thing at a time
Parallel search doesn’t happen in most cases for combinations of individual features. Instead, there is a bottleneck. To put that in context, first let’s remind ourselves of aspects of parallel versus serial processing.
Imagine you were in an art installation where the artist had hung many speakers from the ceiling, and each speaker played a different person’s voice, each telling a different story. That’s pretty weird, but is precisely the situation I was in one day when I visited a museum in Havana, Cuba. What I heard sounded like an incoherent jumble. I couldn’t follow any of the actual stories being told by the voices until I moved my ear up against an individual speaker. In other words, I could only process a single auditory stimulus at a time, and to do so, I had to select it using overt attention.
A forest of speakers is not a situation you are likely to encounter! It does illustrate, however, one possibility for sensory processing - for certain things, you may be unable to process multiple signals at once. In that case, you need to select one stimulus to concentrate on it.

Fortunately, our visual brain can process certain aspects of the visual scene in parallel. But for combinations of features, you are in much the same boat as I was that day in Havana, having to select individual locations to evaluate an aspect of what is present - specifically, the combination of features there.
9.4 Combinations of features - serial search
As children, many of you will have had a book from the Where’s Wally? series.

The game on each page was to search for the Wally character. Sometimes it probably took you a long time to find him. Why was he so hard to find? Wally wore a particular combination of clothing items that you could look for: a horizontal red-and-white striped shirt, a red and white beanie, and blue trousers. The difficulty stemmed from the fact that the artist gave those same features, including horizontal, red, white, and blue, to many other objects and characters in the scene, and human visual search for a combination of features is very time-consuming.
In the below display, your task is to search for the red circle, which is a combination of features - red and circular.

Instead of being able to rely on parallel processing to rapidly tell you where the target is, you have to bring limited resources to bear. Those resources can only process a few objects at a time (they impose a bottleneck). So, the more distractors there are, the longer it takes (on average) to find the target. The below plot shows the average response time as a function of number of distractors.
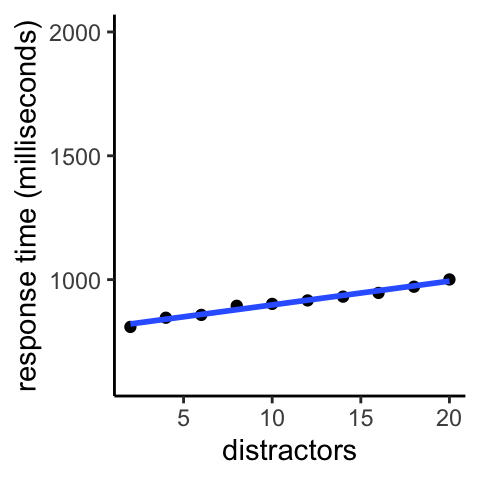
Figure 9.3: Searching for a lone red circle among blue circles and red squares. The average time it takes for a participant to find the target increases steadily with number of distractors.
Now view the below image, which is made up of two displays, the left half and the right half.
On the left half of the display, it should be very easy to find the red vertical item, simply by using feature selection for red.
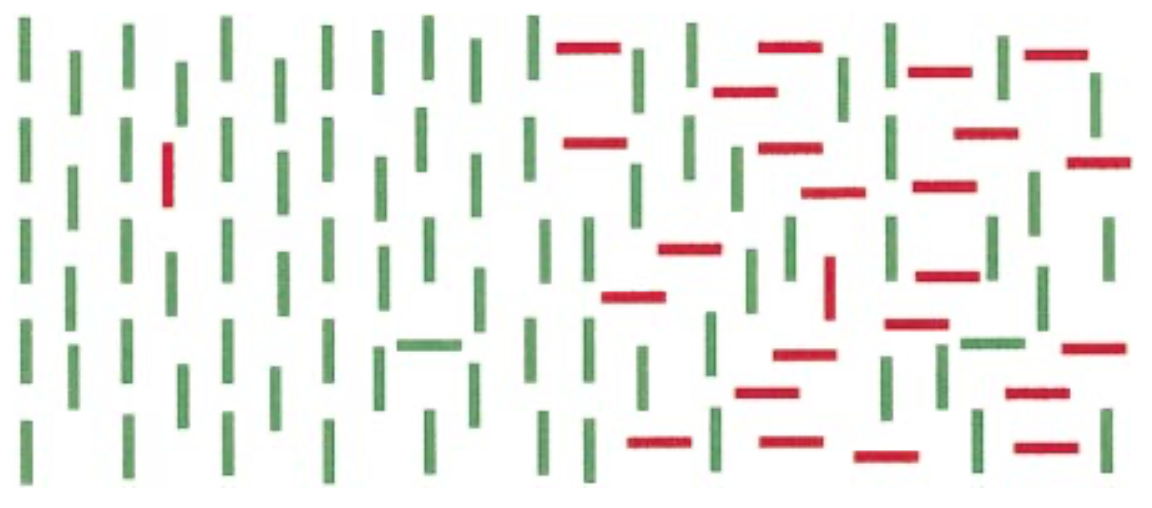
In the right half of the display, searching for the red vertical item is much more difficult. This is because the target differs from the distractors not by a single feature, but rather by a combination of features. This is called conjunction search. That is, conjunction search is search for a target among other objects that have the constituent features of the target, but in different combinations. Here, the target is the only red vertical object, but some other objects are red (but with a different orientation) and some others are vertical (but with a different color).
Assessing combinations of features requires a limited-capacity process. Therefore, attentional selection must rove about the display until the target is found. This was first suggested by Anne Treisman and called “Feature Integration Theory”. Treisman specifically proposed that attention must individualy select each object, to one-by-one to evaluate what combination of features it has. That’s quite the bottleneck!
This search for a red vertical line among green vertical lines and red horizontal lines yields a very similar result for the pattern of response times as did the previous search, for a red circle among blue circles and red squares. Both are conjunction searches.
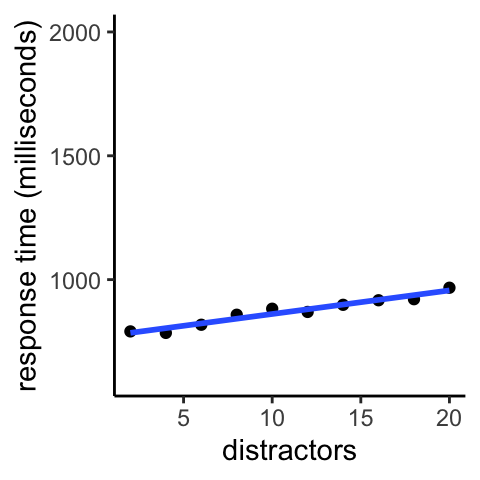
Figure 9.4: Searching for a vertical red line among vertical green lines and horizontal red lines.
The linear slope indicates that each additional distractor imposes a cost. This is expected if one can only evaluate one, or a few, items at a time. The longer it takes to evaluate each item for whether it is the target, the steeper the slope will be. For the graph above, the slope of the line is such that it rises by 100 milliseconds (one-tenth of a second) for every additional ten distractors.
Serial search is the name for this theory that to complete a particular search task, some process in the visual system has to evaluate the stimuli one-by-one, or maybe two-by-two or three-by-three; the point is that it is capacity-limited and thus can’t process all the items at once. Because conjunction search typically has a linear positive slope, many researchers have concluded that such searches do indeed occur serially.
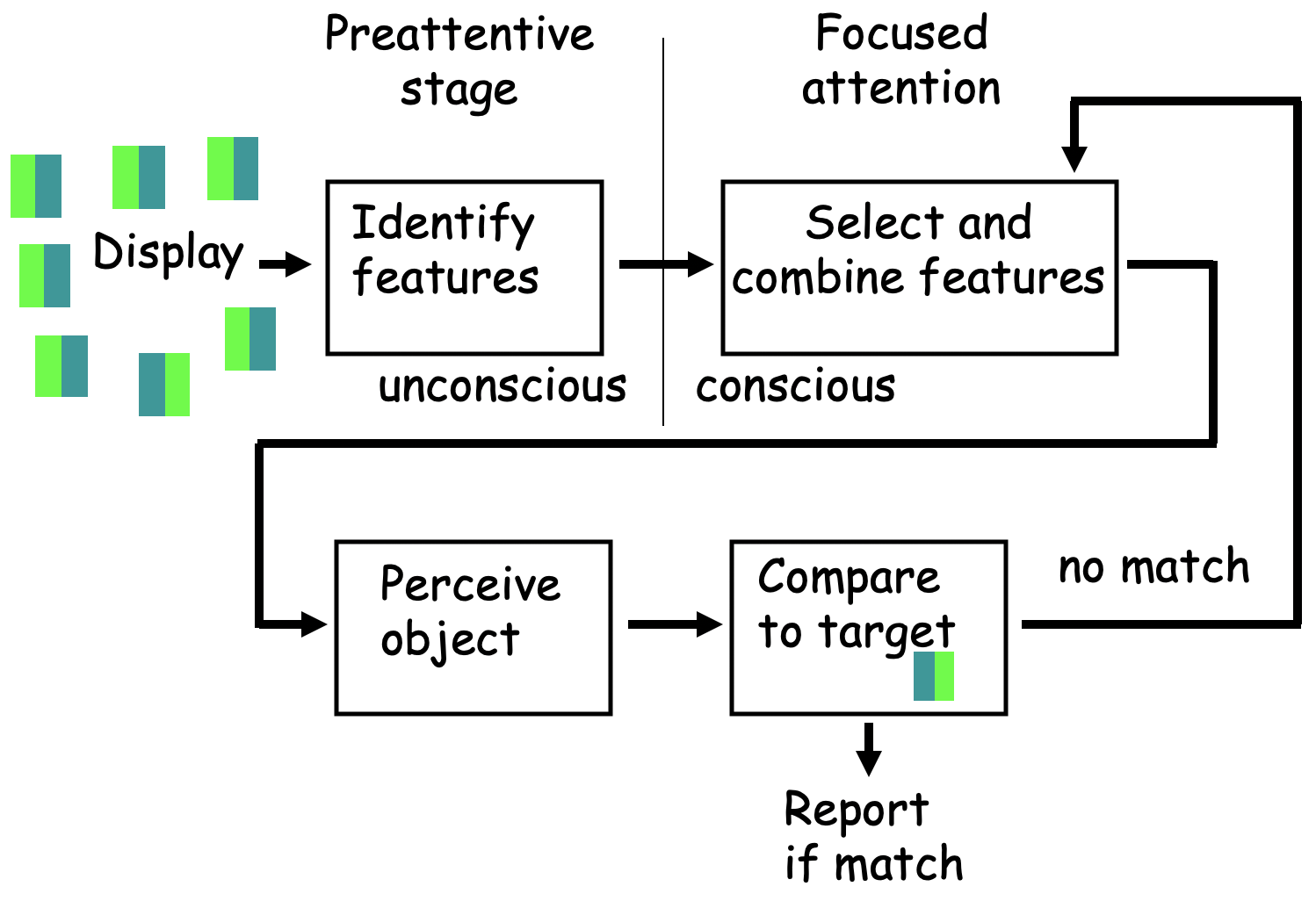
Figure 9.5: The mental processes that may be involved in serial search for a difficult target of dark green on its left, light green on its right. Combining the two features is required, which happens just one object at a time.
In search, if one starts at a random place in the scene and then evaluates each item in a random sequence, on average one will only have to visit half of the items before one lands on the target. Think about it - you’d have to be very unlucky for you to not land on the target until you’d visited every other item in the display. This means that if response time is 100 milliseconds slower when there are 10 more distractors, on average you only had to evaluate half of those distractors in that time, so the search rate is 100 milliseconds / 5 distractors = 20 milliseconds per distractor. So if search was happening one-by-one, people were searching the scene at a rate of about 20 thousands of a second, or 2 hundredths of a second, per item.
Twenty milliseconds per item is pretty fast! That’s fifty items per second. But researchers are not sure whether or not the serial search happened one-by-one. Instead, people might be able to evaluate, say, three items simultaneously. If so, then it’d be evaluating each group of three every sixty milliseconds, or about 16 groups of three per second. That’s still pretty fast, so it doesn’t seem to be something you are very aware of - can you notice yourself moving your attention 16 times a second? I don’t think so.
Next is another search that does not occur in parallel. Look for the red vertical line.
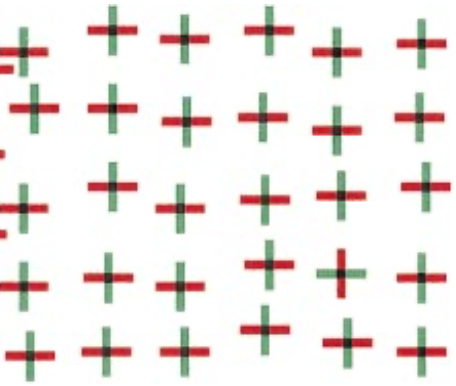
In the above display, vertical items and red items are interspersed throughout, making individual feature selection useless - you really have to evaluate each location for what combination of features is present. Therefore, the more items are in the display, the longer it takes to find the target.
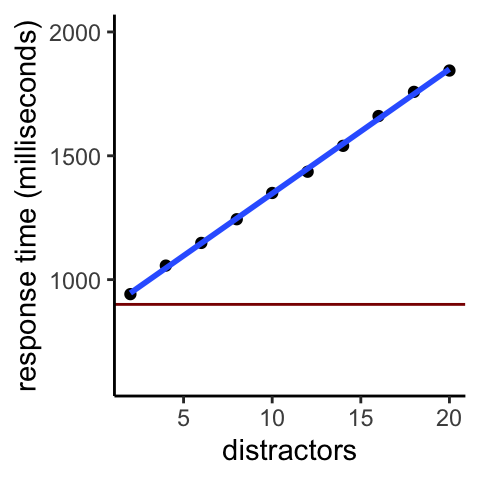
Figure 9.6: Searching for a vertical red line in the crosses display.
The slope of this graph is even steeper than that for the previous two searches. Here, each additional ten distractors increases response time by a full half second (500 ms). That is, the search rate is 50 ms per stimulus, or twenty per second.
To put this in perspective, we can compare the rate at which this feature-combining bottleneck can process things to the rate at which the CPU of a modern computer can process things. Recall that in 3, we explained that the CPU of a computer is a bottleneck. The CPU can only process a little bit of information at a time.
Engineers haven’t found many ways around this problem of the CPU being a bottleneck. However, technological progress has meant that the CPU can make up for its limited capacity with raw speed. The iPhone 11, for example, has a CPU that can perform 2,660,000,000 operations per second. That’s a lot faster than the twenty per second of the above human visual search and helps explain why, despite having a bottleneck like we do, computers can do some things much faster than we can. If you’re interested to learn more about human-computer comparisons, you might consider taking PSYC3014 (Behavioural and Cognitive Neuroscience) next year.
Going back to humans, another case where features need to be combined is when searching for a colored letter. Click on this link and you will be asked to search for an upright orange T with inverted orange Ts and blue Ts as distractors.
9.5 Serial search versus parallel search

Watch an 11 min video about the ‘human visual search engine’ (with an accompanying transcript) starring Jeremy Wolfe that explains more.
Some points to take away from his video:
- Searching for your black cat in a white carpet, it’s easy alone on the white carpet, hard among many other cats (if they have some black).
- In the 1980s, Anne Treisman suggested there are two kinds of searches, serial ones and parallel ones.
- Ts among L’s don’t jump out; search is not parallel. But most people can do 20 to 30 per second because they have so much practice reading.
- For visual scenes, there’s two factors reducing the information you can process in parallel.
- The poor resolution of the visual periphery.
- The lower processing capacity of higher levels.

Now we can connect back to the early versus late selection question that was discussed in PSYC1. Early selection was the idea that there is an early bottleneck - that sensory information is not processed much before the bottleneck. If selection were very early, that would mean identifying features occurs after the bottleneck. Thus the brain identifies only a few features at a time. It’s called “early selection” because selecting something for further processing means doing it early in the system.
Late selection was the idea that the brain is able to process sensory information from across the visual field in parallel. The bottleneck does not occur until much later. It’s called late selection because selecting something for further processing means doing it after a lot of information has already been extracted.
These visual search results suggest that some basic features get processed in parallel, but these features are not integrated into complex shapes or objects. To do that, selection is required. Anne Treisman’s theory of the processing architecture is schematized here
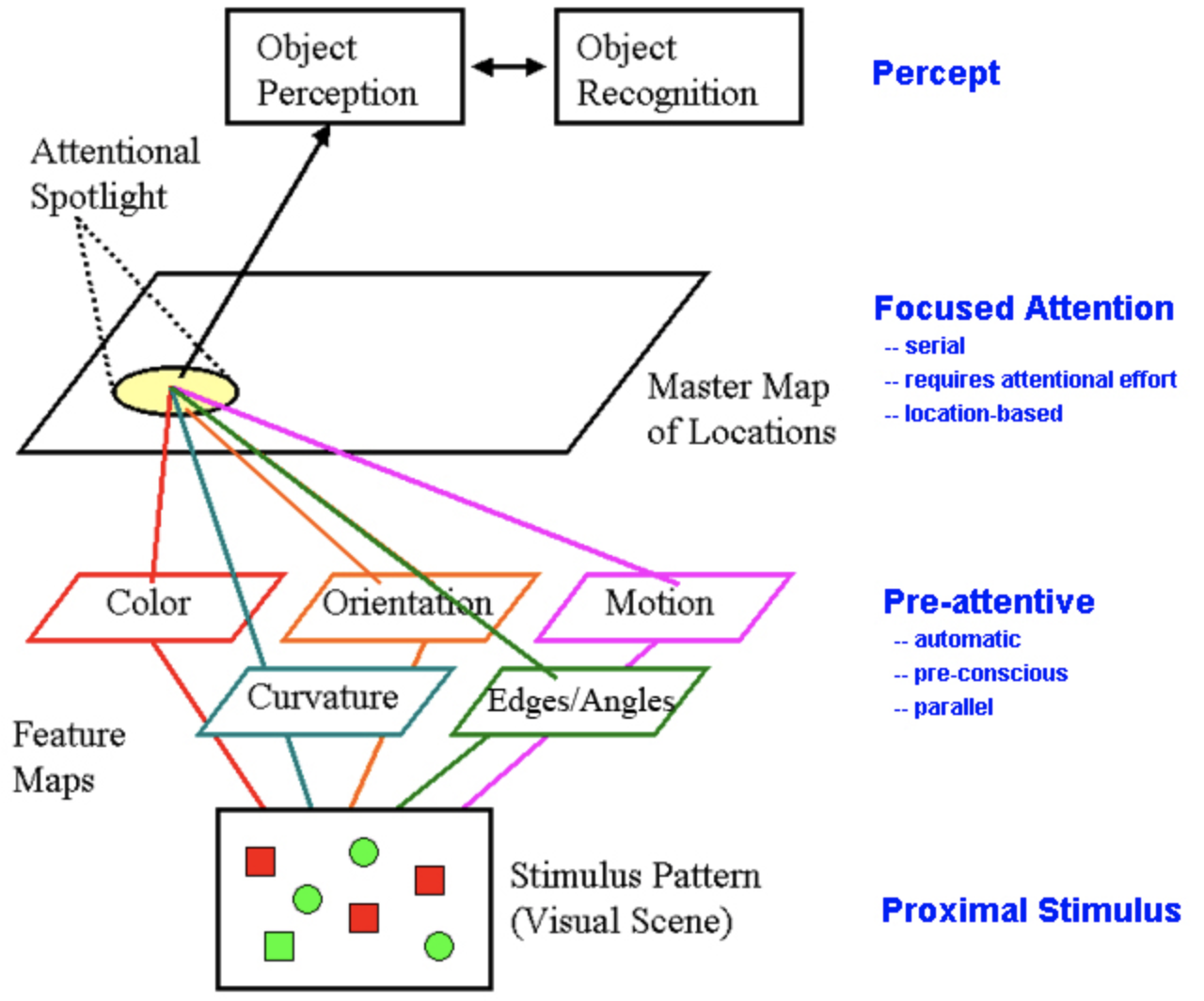
So, selection is after feature processing. This makes it late, relative to feature processing. But selection is before complex shape and object processing. So it is early, relative to complex shape and object processing.
9.6 Visual search and blank-screen sandwiches
Remember the blank-screen sandwich change detection animations of Chapter 6? In a typical blank-screen sandwich experiment, people are timed for how long they take to find the change happening in a photo of a natural scene. To better assess what is happening with attention, one can use a carefully crafted visual search display instead of a natural scene (Rensink 2000).
![]()
As schematized above, the participant was shown blank screen sandwiches with one object changing, and how long it took them to indicate the location of the changing object was recorded. The displays were shown for 800 ms and the blank screen was shown for 120 ms.
Recall from Chapter 6 that with the blank screen in the animation, the flicker/motion detectors provide no clue as to the location of the change. Do you think viewers could use their feature selection ability to help them find the change?
Because the changing object could be any of the objects in the scene, there is no particular feature people can use to find the changing object. All people are left with seems to be a more cognitive process of being able to note that an object one is attending to is no longer what it was - a change has occurred.
Rensink’s hypothesis was that this kind of evaluation process exists after the bottleneck, in the realm of very limited-capacity cognition. So he expected that evaluating whether a change is present can only be done for one or a few items at a time, by attentionally selecting that location so that its features would make their way to cognition where a comparison process could be done over time.
In other words, one has to select the objects in a region with one’s attention to store their appearance before and after the blank screen and then compare them to detect whether they changed. In that case, what do you predict should be the effect on number of items in the display on time to find the object?
Because only a limited number of objects can be simultaneously evaluated for change, the more objects that there are, the longer the task of finding the lone changing object should take. This was borne out by the results:
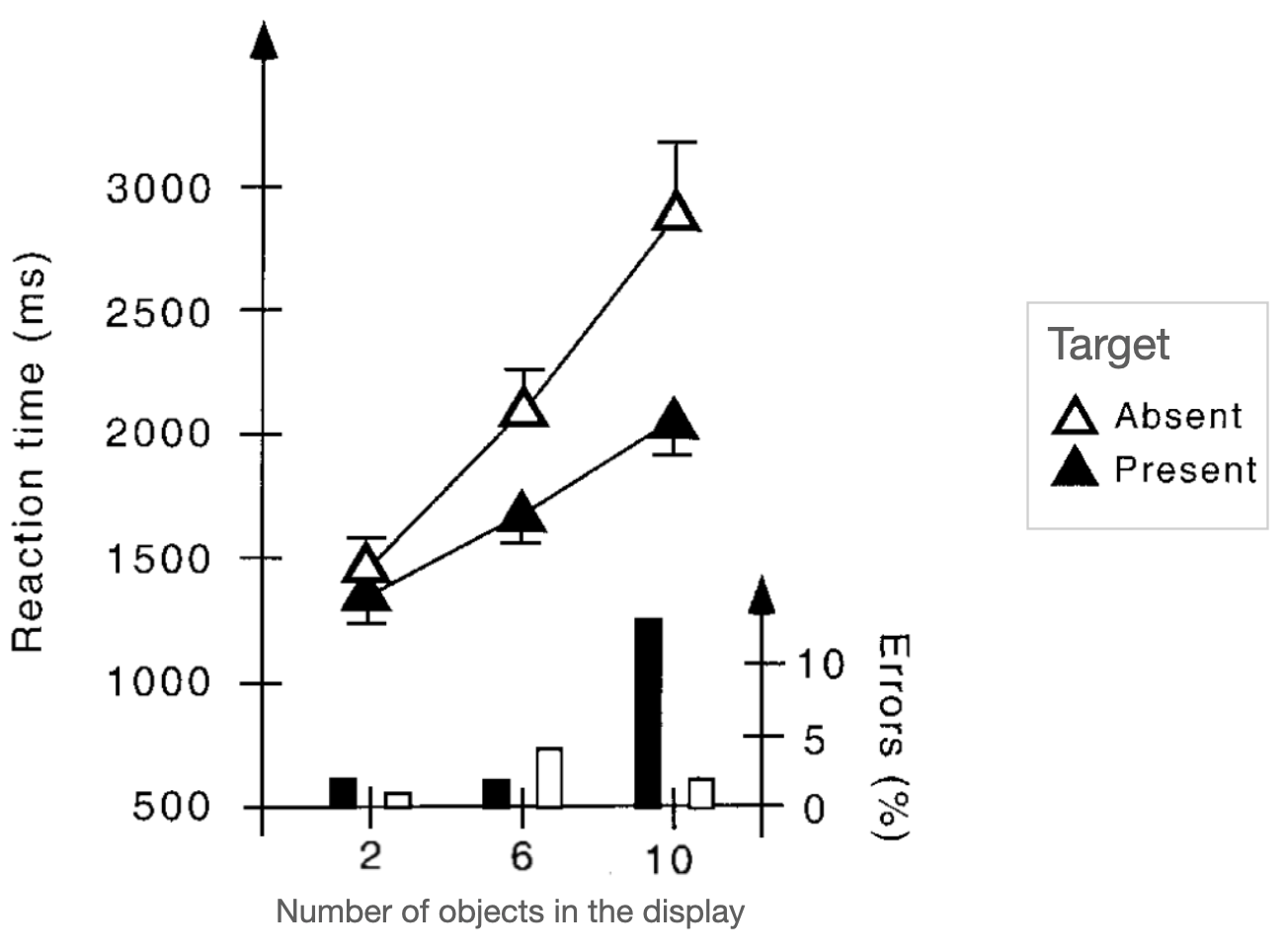
Figure 9.7: Results when searching for a lone changing object in a blank-screen sandwich, from Rensink (2000).
On some trials, the target was absent (the unfilled triangles). In that situation, the participants should not respond until they had evaluated every object in the display so they could be sure nothing was changing, hence the longer response times ( on some occasions, some participants probably got tired of searching and responded prematurely).
9.7 Estimating the processing capacity of cognition’s change detector
A stunning difference between Figure 9.7 and those of the earlier search results graphs (like 9.6) is how much longer the response times are. The response times are all well over a second! Why is that?
Consider what it takes to detect a change. The second picture is not presented until almost a second (920 ms) after the trial begins, so there is no change until then and no way to know what changed until then. The response time of about 1.3 seconds (1300 ms) with only two objects in the display is about as fast as you could expect people to respond - maybe one second before they can detect the change and three-tenths of a second (300 ms) to press the button to indicate they had found the changing stimulus.
Of most interest, then, is not the overall amount of time before a response, but rather the elevation in response time caused by adding more distractors (non-changing objects). If people were able to evaluate all the objects in a display (no capacity limit on change detection), then response times could be the same when there are 10 objects in the display as when there are just 2 objects in the display. Instead, the filled triangles show a steep increase in search time with number of objects in the display.
It’s impossible to evaluate selected objects for change until they change (every 920 milliseconds in this blank screen sandwich). The data plot indicates that on average, 10 objects have to be added to the display to elevate the response time by 920 milliseconds. Because you can find the target on average by searching half the distractors (as mentioned above) this indicates that people could evaluate about 5 objects at a time for whether any one of them was changing. In other words, if on each cycle of the blank screen sandwich they attentionally selected 5 objects and were able to detect whether one of them was changing, this predicts the increase in response time observed in the results.
Let’s sum things up. In Chapter 6 you were reminded of how long it can take people to find a changing object when the flicker/motion does not signal the changing object’s location. The ingenious blank screen sandwich experiment of Rensink (2000) indicates that the reason it takes so long is that people only have the capacity to evaluate about five objects at a time for change. This reflects the very limited processing capacity of the cognitive processing we have to rely on when flicker/motion and feature selection doesn’t help us. Note that Rensink (2000) used very simple objects - oriented lines. The capacity limit may be even worse for more complicated objects.

9.8 Exercises
- Why do people need to move their eyes for many searches?
- What factors can make visual search slow?
- Describe how the kinds of selection connect to visual search performance for different types of display - learning outcome #5 (2).
- How does the finding for visual search performance for feature conjunctions relate to the rate limit found for pairing simultaneous features in the previous chapter?